Neural Networks with Recurrent Generative Feedback
Yujia Huang1, James Gornet1, Sihui Dai1, Zhiding Yu2, Tan Nguyen3, Doris Y. Tsao1, Anima Anandkumar1, 2
1California Institute of Technology
2NVIDIA
3Rice University
Abstract
Neural networks are vulnerable to input perturbations such as additive noise and adversarial attacks. In contrast, human perception is much more robust to such perturbations. The Bayesian brain hypothesis states that human brains use an internal generative model to update the posterior beliefs of the sensory input. This mechanism can be interpreted as a form of self-consistency between the maximum a posteriori (MAP) estimation of an internal generative model and the external environment. Inspired by such hypothesis, we enforce self-consistency in neural networks by incorporating generative recurrent feedback. We instantiate this design on convolutional neural networks (CNNs). The proposed framework, termed Convolutional Neural Networks with Feedback (CNN-F), introduces a generative feedback with latent variables to existing CNN architectures, where consistent predictions are made through alternating MAP inference under a Bayesian framework. In the experiments, CNN-F shows considerably improved adversarial robustness over conventional feedforward CNNs on standard benchmarks.
Introduction
![An intuitive illustration of recurrent generative feedback in human visual perception system. [fig:intuition]](figures/intuition.png)
Vulnerability in feedforward neural networks Conventional deep neural networks (DNNs) often contain many layers of feedforward connections. With the ever-growing network capacities and representation abilities, they have achieved great success. For example, recent convolutional neural networks (CNNs) have impressive accuracy on large scale image classification benchmarks
Feedback in the human brain To address the weaknesses of CNNs, we can take inspiration from of how human visual recognition works, and incorporate certain mechanisms into the CNN design. While human visual cortex has hierarchical feedforward connections, backward connections from higher level to lower level cortical areas are something that current artificial networks are lacking
Predictive coding and generative feedback Computational neuroscientists speculate that Bayesian inference models human perception
Our contributions are as follows:
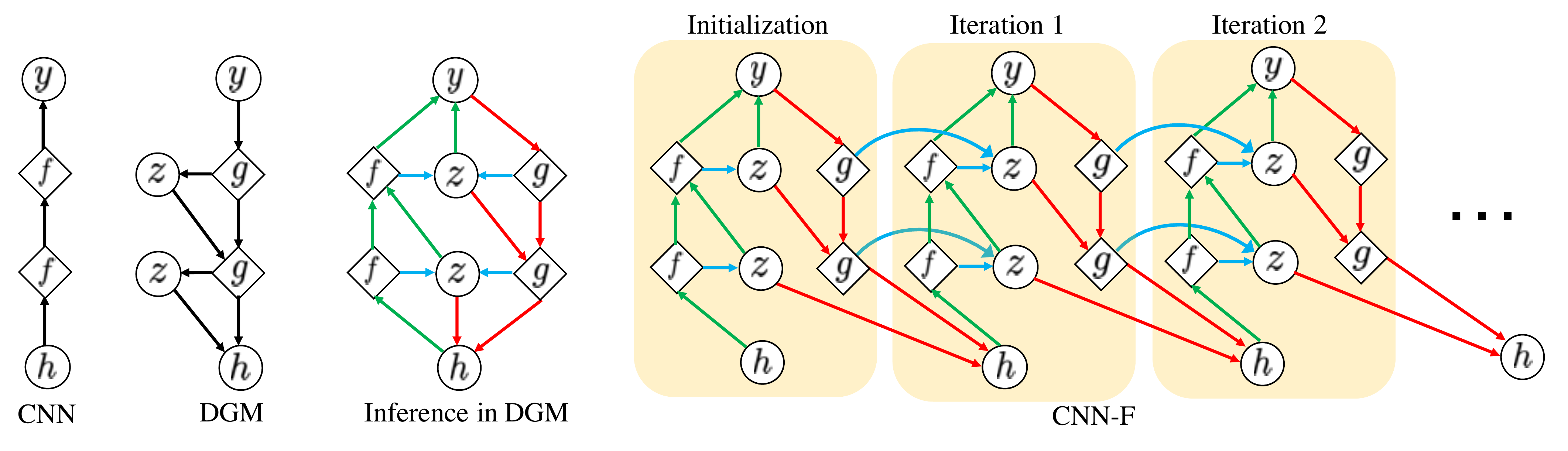
Self-consistency We introduce generative feedback to neural networks and propose the self-consistency formulation for robust perception. Our internal model of the world reaches a self-consistent representation of an external stimulus. Intuitively, self-consistency says that given any two elements of label, image and auxillary information, we should be able to infer the other one. Mathematically, we use a generative model to describe the joint distribution of labels, latent variables and input image features. If the MAP estimate of each one of them are consistent with the other two, we call a label, a set of latent variables and image features to be self-consistent (Figure
CNN with Feedback (CNN-F) We incorporate generative recurrent feedback modeled by the DGM into CNN and term this model as CNN-F. We show that Bayesian inference in the DGM is achieved by CNN with adaptive nonlinear operators (Figure
Adversarial robustness We show that the recurrent generative feedback in CNN-F promotes robustness and visualizes the behavior of CNN-F over iterations. We find that more iterations are needed to reach self-consistent prediction for images with larger perturbation, indicating that recurrent feedback is crucial for recognizing challenging images. When combined with adversarial training, CNN-F further improves adversarial robustness of CNN on both Fashion-MNIST and CIFAR-10 datasets.
Approach
In this section, we first formally define self-consistency. Then we give a specific form of generative feedback in CNN and impose self-consistency on it. We term this model as CNN-F. Finally we show the training and testing procedure in CNN-F. Throughout, we use the following notations:
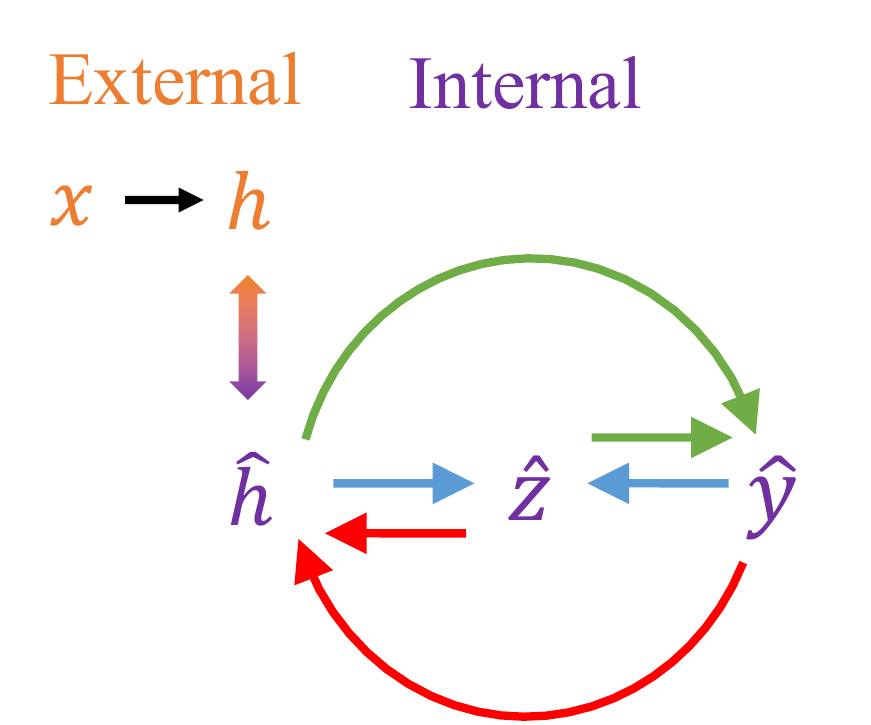
Let x ∈ ℝn be the input of a network and y ∈ ℝK be the output. In image classification, x is image and y = (y(1), …, y(K)) is one-hot encoded label. K is the total number of classes. K is usually much less than n. We use L to denote the total number of network layers, and index the input layer to the feedforward network as layer 0. Let h ∈ ℝm be encoded feature of x at layer k of the feedforward pathway. Feedforward pathway computes feature map f(ℓ) from layer 0 to layer L, and feedback pathway generates g(ℓ) from layer L to k. g(ℓ) and f(ℓ) have the same dimensions. To generate h from y, we introduce latent variables for each layer of CNN. Let z(ℓ) ∈ ℝC × H × W be latent variables at layer ℓ, where C, H, W are the number of channels, height and width for the corresponding feature map. Finally, p(h, y, z; θ) denotes the joint distribution parameterized by θ, where θ includes the weight W and bias term b of convolution and fully connected layers. We use ĥ, ŷ and ẑ to denote the MAP estimates of h, y, z conditioning on the other two variables.
Generative feedback and Self-consistency
Human brain and neural networks are similar in having a hierarchical structure. In human visual perception, external stimuli are first preprocessed by lateral geniculate nucleus (LGN) and then sent to be processed by V1, V2, V4 and Inferior Temporal (IT) cortex in the ventral cortical visual system. Conventional NN use feedforward layers to model this process and learn a one-direction mapping from input to output. However, numerous studies suggest that in addition to the feedforward connections from V1 to IT, there are feedback connections among these cortical areas
Inspired by the Bayesian brain hypothesis and the predictive coding theory, we propose to add generative feedback connections to NN. Since h is usually of much higher dimension than y, we introduce latent variables z to account for the information loss in the feedforward process. We then propose to model the feedback connections as MAP estimation from an internal generative model that describes the joint distribution of h, z and y. Furthermore, we realize recurrent feedback by imposing self-consistency (Definition
(Self-consistency) Given a joint distribution p(h, y, z; θ) parameterized by θ, (ĥ, ŷ, ẑ) are self-consistent if they satisfy the following constraints:
$$\begin{aligned}
\label{eqn:selfconsis}
{\hat{y}}= \arg\,\max_y p(y|{\hat{h}},{\hat{z}}), \qquad
{\hat{h}}= \arg\,\max_h p(h|{\hat{y}},{\hat{z}}), \qquad
{\hat{z}}= \arg\,\max_z p(z|{\hat{h}},{\hat{y}}) \end{aligned}$$
In words, self-consistency means that MAP estimates from an internal generative model are consistent with each other. In addition to self-consistency, we also impose the consistency constraint between ĥ and the external input features (Figure
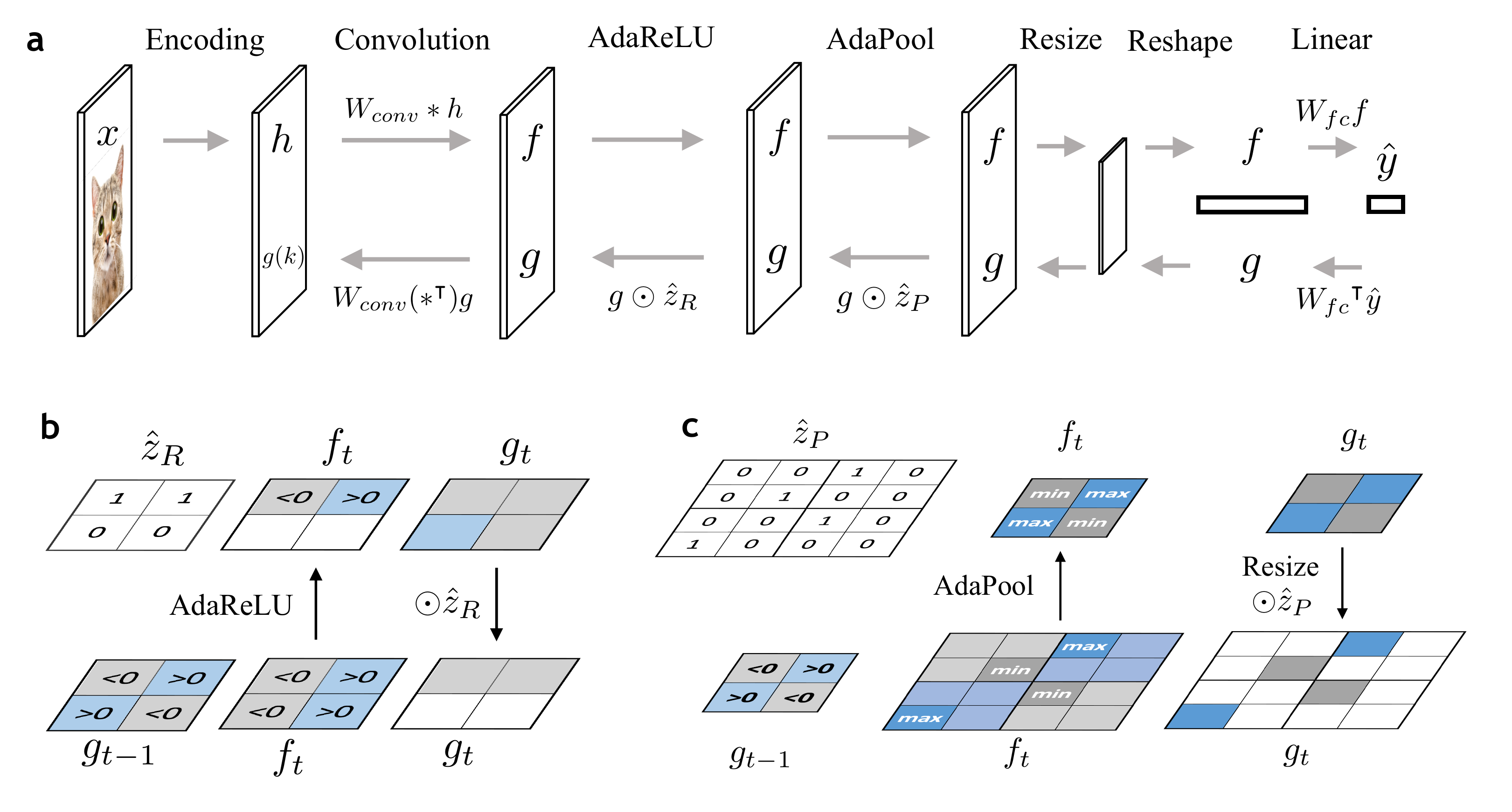
Generative Feedback in CNN-F
CNN have been used to model the hierarchical structure of human retinatopic fields
We choose to use the DGM
g(ℓ − 1) = W(*⊺)(ℓ)(z(ℓ) ⊙ g(ℓ))
In this paper, we assume p(y) to be uniform, which is realistic under the balanced label scenario. We assume that h follows Gaussian distribution centered at g(k) with standard deviation σ.
Recurrence in CNN-F
In this section, we show that self-consistent (ĥ, ŷ, ẑ) in the DGM can be obtained via alternately propagating along feedforward and feedback pathway in CNN-F.
Feedforward and feedback pathway in CNN-F
The feedback pathway in CNN-F takes the same form as the generation process in the DGM (Equation (
$${\sigma_{\text{AdaReLU}}}(f) =
\begin{cases}
{\sigma_{\text{ReLU}}}(f), \quad\text{if } g \geq 0 \\
{\sigma_{\text{ReLU}}}(-f), \quad\text{if } g<0
\end{cases}
\quad
{\sigma_{\text{AdaPool}}}(f) =
\begin{cases}
{\sigma_{\text{MaxPool}}}(f), \quad\text{if } g \geq 0 \\
-{\sigma_{\text{MaxPool}}}(-f), \quad\text{if } g<0
\end{cases}$$
MAP inference in the DGM
Given a joint distribution of h, y, z modeled by the DGM, we aim to show that we can make predictions using a CNN architecture following the Bayes rule (Theorem
Assumption 2
(Constancy assumption in the DGM). A. The generated image g(k) at layer k of DGM satisfies ||g(k)||22 = const. B. Prior distribution on the label is a uniform distribution: p(y) = const. C. Normalization factor in p(z|y) for each category is constant: ∑zeη(y, z) = const.
To meet Assumption
Theorem 5
Under Assumption
Please refer to Appendix.
Theorem
We also find the form of MAP inference for image feature ĥ and latent variables ẑ in the DGM. Specifically, we use zR and zP to denote latent variables that are at a layer followed by AdaReLU and AdaPool respectively. 𝟙( ⋅ ) denotes indicator function.
Proposition 6
[MAP inference in the DGM] Under Assumption
A. Let h be the feature at layer k, then ĥ = g(k).
B. MAP estimate of z(ℓ) conditioned on h, y and {z(j)}j ≠ ℓ in the DGM is:
$$\begin{aligned}
{\hat{z}}_{R}(\ell) &= \mathbb{1}{({\sigma_{\text{AdaReLU}}}(f(\ell)) \geq 0)} \\
{\hat{z}}_{P}(\ell) &= \mathbb{1}{(g(\ell) \geq 0)}\odot \arg\,\max_{r\times r} (f(\ell))
+ \mathbb{1}{(g(\ell)<0)}\odot \arg\,\min_{r\times r} (f(\ell)) \label{eqn:mainlatentp}\end{aligned}$$
Proof
For part A, we have ĥ = arg maxhp(h|ŷ, ẑ) = arg maxhp(h|g(k)) = g(k). The second equality is obtained because g(k) is a deterministic function of ŷ and ẑ. The third equality is obtained because h ∼ 𝒩(g(k), diag(σ2)). For part B, please refer to Appendix.
Remark
Proposition
Proposition
Iterative inference and online update in CNN-F
We find self-consistent (ĥ, ŷ, ẑ) by iterative inference and online update (Algorithm
$$\begin{aligned}
{\hat{h}}_{t+1} & \leftarrow {\hat{h}}_t + \eta (g_{t+1}(k) - {\hat{h}}_t) \label{eqn:upd_h} \\
f_{t+1}(\ell) & \leftarrow f_{t+1}(\ell) + \eta (g_t(\ell) - f_{t+1}(\ell)), \ell=k,\dots,L \label{eqn:upd_f}\end{aligned}$$
where η is the step size. Greedily replacement is a special case for the online update rule when η = 1.
Encode image x to h0 with k convolutional layers Initialize {ẑ(ℓ)}ℓ = k : L by σReLU and σMaxPool in the standard CNN
Training the CNN-F
During training, we have three goals: 1) train a generative model to model the data distribution, 2) train a generative classifier and 3) enforce self-consistency in the model. We first approximate self-consistent (ĥ, ŷ, ẑ) and then update model parameters based on the losses listed in Table
Table
| Form | Purpose | |
| Cross-entropy loss | log p(y | ĥt, ẑt; θ) | classification |
| Reconstruction loss | log p(h | ŷt, ẑt; θ) = ||h − ĥ||22. | generation, self-consistency |
| Intermediate reconstruction loss | ||f0(ℓ) − gt(ℓ)||22 | stabilizing training |
Experiment
Generative feedback promotes robustness
As a sanity check, we train a CNN-F model with two convolution layers and one fully-connected layer on clean Fashion-MNIST images. We expect that CNN-F reconstructs the perturbed inputs to their clean version and makes self-consistent predictions. To this end, we verify the hypothesis by evaluating adversarial robustness of CNN-F and visualizing the restored images over iterations.
Adversarial robustness
Since CNN-F is an iterative model, we consider two attack methods: attacking the first or last output from the feedforward streams. We use “first” and “e2e” (short for end-to-end) to refer to the above two attack approaches, respectively. Due to the approximation of non-differentiable activation operators and the depth of the unrolled CNN-F, end-to-end attack is weaker than first attack (Appendix). We report the adversarial accuracy against the stronger attack in Figure
Figure

Image restoration
Given that CNN-F models are robust to adversarial attacks, we examine the models’ mechanism for robustness by visualizing how the generative feedback moves a perturbed image over iterations. We select a validation image from Fashion-MNIST. Using the image’s two largest principal components, a two-dimensional hyperplane ⊂ ℝ28 × 28 intersects the image with the image at the center. Vector arrows visualize the generative feedback’s movement on the hyperplane’s position. In Figure
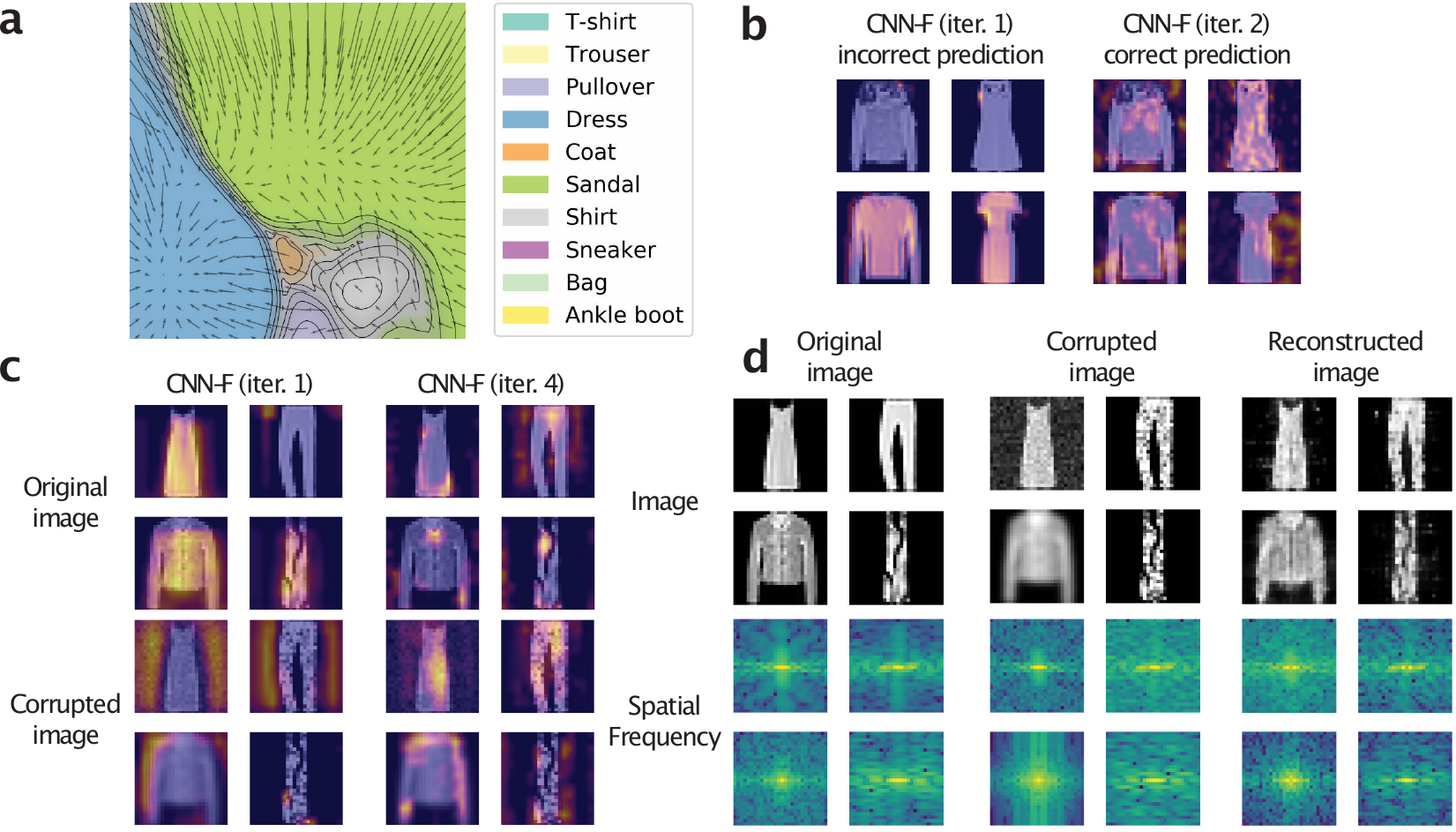
We further explore this principle with regard to adversarial examples. The CNN-F model can correct initially wrong predictions. Figure
Adversarial Training
![Loss design for CNN-F adversarial training, where v stands for the logits. x, h and g are input image, encoded feature, and generated feature, respectively. [fig:advtrainloss]](figures/advloss.png)
Adversarial training is a well established method to improve adversarial robustness of a neural network
Training methods
Figure
Experimental setup
We train the CNN-F on Fashion-MNIST and CIFAR-10 datasets respectively. For Fashion-MNIST, we train a network with 4 convolution layers and 3 fully-connected layers. We use 2 convolutional layers to encode the image into feature space and reconstruct to that feature space. For CIFAR-10, we use the WideResNet architecture
Main results
CNN-F further improves the robustness of CNN when combined with adversarial training. Table
Table
| Clean | PGD (first) | PGD (e2e) | SPSA (first) | SPSA (e2e) | Transfer | Min | |
| CNN | 89.97 ± 0.10 | 77.09 ± 0.19 | 77.09 ± 0.19 | 87.33 ± 1.14 | 87.33 ± 1.14 | — | 77.09 ± 0.19 |
| CNN-F (last) | 89.87 ± 0.14 | 79.19 ± 0.49 | 78.34 ± 0.29 | 87.10 ± 0.10 | 87.33 ± 0.89 | 82.76 ± 0.26 | 78.34 ± 0.29 |
| CNN-F (avg) | 89.77 ± 0.08 | 79.55 ± 0.15 | 79.89 ± 0.16 | 88.27 ± 0.91 | 88.23 ± 0.81 | 83.15 ± 0.17 | 79.55 ± 0.15 |
Table
| Clean | PGD (first) | PGD (e2e) | SPSA (first) | SPSA (e2e) | Transfer | Min | |
| CNN | 79.09 ± 0.11 | 42.31 ± 0.51 | 42.31 ± 0.51 | 66.61 ± 0.09 | 66.61 ± 0.09 | — | 42.31 ± 0.51 |
| CNN-F (last) | 78.68 ± 1.33 | 48.90 ± 1.30 | 49.35 ± 2.55 | 68.75 ± 1.90 | 51.46 ± 3.22 | 66.19 ± 1.37 | 48.90 ± 1.30 |
| CNN-F (avg) | 80.27 ± 0.69 | 48.72 ± 0.64 | 55.02 ± 1.91 | 71.56 ± 2.03 | 58.83 ± 3.72 | 67.09 ± 0.68 | 48.72 ± 0.64 |
Related work
Robust neural networks with latent variables
Latent variable models are a unifying theme in robust neural networks. The consciousness prior
Computational models of human vision
Recurrent models and Bayesian inference have been two prevalent concepts in computational visual neuroscience. Recently,
Feedback networks
Feedback Network
Combining top-down and bottom-up signals in RNNs
Inference in generative classifiers
Target propagation
The generative feedback in CNN-F shares a similar form as target propagation, where the targets at each layer are propagated backwards. In addition, difference target propagation uses auto-encoder like losses at intermediate layers to promote network invertibility
Conclusion
Inspired by the recent studies in Bayesian brain hypothesis, we propose to introduce recurrent generative feedback to neural networks. We instantiate the framework on CNN and term the model as CNN-F. In the experiments, we demonstrate that the proposed feedback mechanism can considerably improve the adversarial robustness compared to conventional feedforward CNNs. We visualize the dynamical behavior of CNN-F and show its capability of restoring corrupted images. Our study shows that the generative feedback in CNN-F presents a biologically inspired architectural design that encodes inductive biases to benefit network robustness.
Broader Impacts
Convolutional neural networks (CNNs) can achieve superhuman performance on image classification tasks. This advantage allows their deployment to computer vision applications such as medical imaging, security, and autonomous driving. However, CNNs trained on natural images tend to overfit to image textures. Such flaw can cause a CNN to fail against adversarial attacks and on distorted images. This may further lead to unreliable predictions potentially causing false medical diagnoses, traffic accidents, and false identification of criminal suspects. To address the robustness issues in CNNs, CNN-F adopts an architectural design which resembles human vision mechanisms in certain aspects. The deployment of CNN-F renders more robust AI systems.
Despite the improved robustness, current method does not tackle other social and ethical issues intrinsic to a CNN. A CNN can imitate human biases in the image datasets. In automated surveillance, biased training datasets can improperly calibrate CNN-F systems to make incorrect decisions based on race, gender, and age. Furthermore, while robust, human-like computer vision systems can provide a net positive societal impact, there exists potential use cases with nefarious, unethical purposes. More human-like computer vision algorithms, for example, could circumvent human verification software. Motivated by these limitations, we encourage research into human bias in machine learning and security in computer vision algorithms. We also recommend researchers and policymakers examine how people abuse CNN models and mitigate their exploitation.
Acknowledgements
We thank Chaowei Xiao, Haotao Wang, Jean Kossaifi, Francisco Luongo for the valuable feedback. Y. Huang is supported by DARPA LwLL grants. J. Gornet is supported by supported by the NIH Predoctoral Training in Quantitative Neuroscience 1T32NS105595-01A1. D. Y. Tsao is supported by Howard Hughes Medical Institute and Tianqiao and Chrissy Chen Institute for Neuroscience. A. Anandkumar is supported in part by Bren endowed chair, DARPA LwLL grants, Tianqiao and Chrissy Chen Institute for Neuroscience, Microsoft, Google, and Adobe faculty fellowships.
Athalye, Anish, Nicholas Carlini, and David Wagner. 2018. “Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples.” In ICLR.
Bengio, Yoshua. 2019. “The Consciousness Prior.” arXiv:1709.08568.
Dodge, S., and L. Karam. 2017. “A Study and Comparison of Human and Deep Learning Recognition Performance Under Visual Distortions.” In ICCCN.
Eickenberg, Michael, Alexandre Gramfort, Gaël Varoquaux, and Bertrand Thirion. 2017. “Seeing It All: Convolutional Network Layers Map the Function of the Human Visual System.” NeuroImage. Elsevier.
Elsayed, Gamaleldin, Shreya Shankar, Brian Cheung, Nicolas Papernot, Alexey Kurakin, Ian Goodfellow, and Jascha Sohl-Dickstein. 2018. “Adversarial Examples That Fool Both Computer Vision and Time-Limited Humans.” In NeurIPS.
Felleman, D. J., and D. C. Van Essen. 1991. “Distributed Hierarchical Processing in the Primate Cerebral Cortex.” Cerebral Cortex.
George, Dileep, Wolfgang Lehrach, Ken Kansky, Miguel Lázaro-Gredilla, Christopher Laan, Bhaskara Marthi, Xinghua Lou, et al. 2017. “A Generative Vision Model That Trains with High Data Efficiency and Breaks Text-Based CAPTCHAs.” Science.
Goodfellow, Ian J., Jonathon Shlens, and Christian Szegedy. 2015. “Explaining and Harnessing Adversarial Examples.” In ICLR.
Goyal, Anirudh, Alex Lamb, Jordan Hoffmann, Shagun Sodhani, Sergey Levine, Yoshua Bengio, and Bernhard Schölkopf. 2019. “Recurrent Independent Mechanisms.” arXiv:1909.10893.
Horikawa, Tomoyasu, and Yukiyasu Kamitani. 2017. “Hierarchical Neural Representation of Dreamed Objects Revealed by Brain Decoding with Deep Neural Network Features.” Front Comput Neurosci. Frontiers.
Kar, Kohitij, Jonas Kubilius, Kailyn Schmidt, Elias B Issa, and James J DiCarlo. 2019. “Evidence That Recurrent Circuits Are Critical to the Ventral Stream’s Execution of Core Object Recognition Behavior.” Nature Neuroscience.
Kietzmann, Tim C, Courtney J Spoerer, Lynn KA Sörensen, Radoslaw M Cichy, Olaf Hauk, and Nikolaus Kriegeskorte. 2019. “Recurrence Is Required to Capture the Representational Dynamics of the Human Visual System.” PNAS. National Acad Sciences.
Knill, David C, and Whitman Richards. 1996. Perception as Bayesian Inference. Cambridge University Press.
Kok, Peter, Janneke FM Jehee, and Floris P De Lange. 2012. “Less Is More: Expectation Sharpens Representations in the Primary Visual Cortex.” Neuron. Elsevier.
Kubilius, Jonas, Martin Schrimpf, Aran Nayebi, Daniel Bear, Daniel LK Yamins, and James J DiCarlo. 2018. “CORnet: Modeling the Neural Mechanisms of Core Object Recognition.” bioRxiv Preprint. Cold Spring Harbor Laboratory.
Lamb, Alex, Jonathan Binas, Anirudh Goyal, Sandeep Subramanian, Ioannis Mitliagkas, Denis Kazakov, Yoshua Bengio, and Michael C. Mozer. 2019. “State-Reification Networks: Improving Generalization by Modeling the Distribution of Hidden Representations.” In ICML.
Lee, Dong-Hyun, Saizheng Zhang, Asja Fischer, and Yoshua Bengio. 2015. “Difference Target Propagation.” In ECML-Pkdd.
Linsley, Drew, Junkyung Kim, Vijay Veerabadran, Charles Windolf, and Thomas Serre. 2018. “Learning Long-Range Spatial Dependencies with Horizontal Gated Recurrent Units.” In NeurIPS.
Madry, Aleksander, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. 2017. “Towards Deep Learning Models Resistant to Adversarial Attacks.” arXiv:1706.06083.
Meng, Dongyu, and Hao Chen. 2017. “MagNet: A Two-Pronged Defense Against Adversarial Examples.” In CCS.
Meulemans, Alexander, Francesco S Carzaniga, Johan AK Suykens, João Sacramento, and Benjamin F Grewe. 2020. “A Theoretical Framework for Target Propagation.” arXiv:2006.14331.
Mittal, Sarthak, Alex Lamb, Anirudh Goyal, Vikram Voleti, Murray Shanahan, Guillaume Lajoie, Michael Mozer, and Yoshua Bengio. 2020. “Learning to Combine Top-down and Bottom-up Signals in Recurrent Neural Networks with Attention over Modules.” In ICML.
Nayebi, Aran, Daniel Bear, Jonas Kubilius, Kohitij Kar, Surya Ganguli, David Sussillo, James J DiCarlo, and Daniel L Yamins. 2018. “Task-Driven Convolutional Recurrent Models of the Visual System.” In NeurIPS.
Nguyen, Tan, Nhat Ho, Ankit Patel, Anima Anandkumar, Michael I. Jordan, and Richard G. Baraniuk. 2018. “A Bayesian Perspective of Convolutional Neural Networks Through a Deconvolutional Generative Model.” arXiv:1811.02657.
Nimmagadda, Tejaswi, and Anima Anandkumar. 2015. “Multi-Object Classification and Unsupervised Scene Understanding Using Deep Learning Features and Latent Tree Probabilistic Models.” arXiv:1505.00308.
Piekniewski, Filip, Patryk Laurent, Csaba Petre, Micah Richert, Dimitry Fisher, and Todd Hylton. 2016. “Unsupervised Learning from Continuous Video in a Scalable Predictive Recurrent Network.” arXiv:1607.06854.
Rao, Rajesh P. N., and Dana H. Ballard. 1999. “Predictive Coding in the Visual Cortex: A Functional Interpretation of Some Extra-Classical Receptive-Field Effects.” Nature Neuroscience.
Samangouei, Pouya, Maya Kabkab, and Rama Chellappa. 2018. “Defense-Gan: Protecting Classifiers Against Adversarial Attacks Using Generative Models.” In ICLR.
Selvaraju, Ramprasaath R, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. 2017. “Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization.” In ICCV.
Sulam, Jeremias, Aviad Aberdam, Amir Beck, and Michael Elad. 2019. “On Multi-Layer Basis Pursuit, Efficient Algorithms and Convolutional Neural Networks.” IEEE Trans. PAMI.
Szegedy, Christian, Vincent Vanhoucke, Sergey Ioffe, Jonathon Shlens, and Zbigniew Wojna. 2016. “Rethinking the Inception Archi-Tecture for Computer Vision.” In CVPR.
Szegedy, Christian, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfellow, and Rob Fergus. 2014. “Intriguing Properties of Neural Networks.” In ICLR.
Uesato, Jonathan, Brendan O’Donoghue, Aaron van den Oord, and Pushmeet Kohli. 2018. “Adversarial Risk and the Dangers of Evaluating Against Weak Attacks.” In ICML.
Ulyanov, Dmitry, Andrea Vedaldi, and Victor Lempitsky. 2016. “Instance Normalization: The Missing Ingredient for Fast Stylization.” arXiv:1607.08022.
Wang, Tianlu, Kota Yamaguchi, and Vicente Ordonez. 2018. “Feedback-Prop: Convolutional Neural Network Inference Under Partial Evidence.” In CVPR.
Warde-Farley, David, and Yoshua Bengio. 2017. “Improving Generative Adversarial Networks with Denoising Feature Matching.” In ICLR.
Wen, Haiguang, Kuan Han, Junxing Shi, Yizhen Zhang, Eugenio Culurciello, and Zhongming Liu. 2018. “Deep Predictive Coding Network for Object Recognition.” In ICML.
Zagoruyko, Sergey, and Nikos Komodakis. 2016. “Wide Residual Networks.” arXiv:1605.07146.
Zamir, Amir R., Te-Lin Wu, Lin Sun, William B. Shen, Bertram E. Shi, Jitendra Malik, and Silvio Savarese. 2017. “Feedback Networks.” In CVPR.
σ takes the form of σAdaPool or σAdaReLU.↩