Reconstructing neuronal anatomy from whole-brain images
James Gornet1, ⋆, Kannan Umadevi Venkataraju2, Arun Narasimhan2, Nicholas Turner3, Kisuk Lee4, H. Sebastian Seung3, Pavel Osten2, Uygar Sümbül5
1 Columbia University, Department of Biomedical Engineering, New York, NY, USA
2 Cold Spring Harbor Laboratory, Department of Neuroscience, Cold Spring Harbor, NY, USA
3 Princeton Neuroscience Institute and Computer Science Department, Princeton, NJ, USA
4 Massachusetts Institute of Technology, Department of Brain and Cognitive Sciences, Cambridge, MA, USA
5 Allen Institute for Brain Science, Seattle, WA, USA
Abstract
Reconstructing multiple molecularly defined neurons from individual brains and across multiple brain regions can reveal organizational principles of the nervous system. However, high resolution imaging of the whole brain is a technically challenging and slow process. Recently, oblique light sheet microscopy has emerged as a rapid imaging method that can provide whole brain fluorescence microscopy at a voxel size of 0.4 × 0.4 × 2.5 μm3. On the other hand, complex image artifacts due to whole-brain coverage produce apparent discontinuities in neuronal arbors. Here, we present connectivity-preserving methods and data augmentation strategies for supervised learning of neuroanatomy from light microscopy using neural networks. We quantify the merit of our approach by implementing an end-to-end automated tracing pipeline. Lastly, we demonstrate a scalable, distributed implementation that can reconstruct the large datasets that sub-micron whole-brain images produce.
Introduction
Understanding the principles guiding neuronal organization has been a major goal in neuroscience. The ability to reconstruct individual neuronal arbors is necessary, but not sufficient to achieve this goal: understanding how neurons of the same and different types co-locate themselves requires the reconstruction of the arbors of multiple neurons sharing similar molecular and/or physiological features from the same brain. Such denser reconstructions may allow the field to answer some of the fundamental questions of neuroanatomy: do cells of the same type tile across the lateral dimensions by avoiding each other? To what extent do the organizational principles within a brain region extend across the whole brain? While dense reconstruction of electron microscopy images provides a solution
Recent advances in tissue clearing
The U-Net architecture
In addition to accuracy, an efficient, scalable implementation is necessary for reconstructing petavoxel-sized image datasets. We maintain scalability and increase the throughput by using a distributed framework for reconstructing neurons from brain images, in which the computation can be distributed across multiple GPU instances. Finally, we augment data at run-time to avoid memory issues and computational bottlenecks. This significantly increases the throughput rate because data transfers are a substantial bottleneck. We report segmentation speeds exceeding 300 gigavoxels per hour and linear speedups in the presence of additional GPUs.
Methods
Convolutional neural network regularization through digital topology techniques
To create the training set, we obtain volumetric reconstructions of the manual arbor traces of neuronal images by a topology-preserving inflation of the traces
$$\label{equ:loss}
% J(\hat{y}, y) = -\frac{1}{N}\sum^{N}_{i=1} w_{i} \big[ y_{i} \log
% (\sigma(\hat{y}_{i})) + (1 - y_{i}) \log (1 - {\sigma(\hat{y}_{i})})
% \big]
J(\hat{y}, y) = -\frac{1}{N}\sum^{N}_{i=1} w_{i} \big[ y_{i} \log
(\hat{y}_{i}) + (1 - y_{i}) \log (1 - {\hat{y}_{i}})
\big]$$
where wi = w > 1 if voxel i is non-simple while wi = 1 otherwise, N is the number of voxels, and yi and $\hat{y_i}$ are the label image and predicted segmentation, respectively. Note that the simple-ness of a voxel depends only on its 26-neighborhood, and therefore this operation scales linearly with the patch size.
Simulation of image artifacts through data augmentations
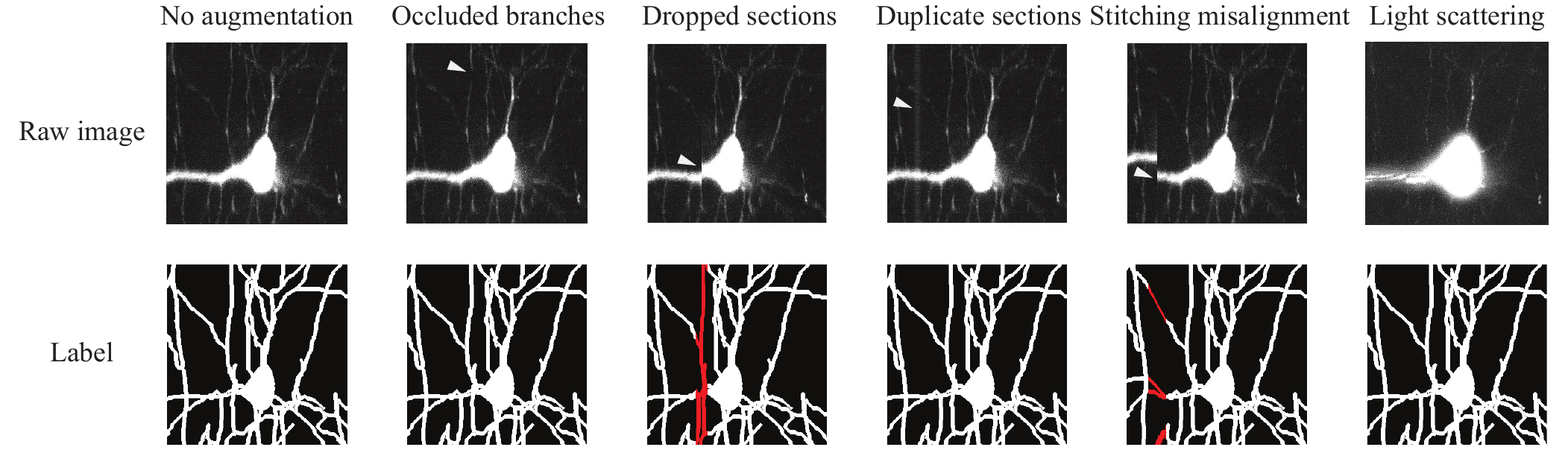
Data augmentation is a technique that augments the base training data with pre-defined transformations of it. By creating statistical invariances (e.g. against rotation) within the dataset or over-representing rarely occurring artifacts, augmentation can increase the robustness of the learned algorithm. Motivated by the fact that 3D microscopy is prone to several image artifacts, we followed a unified framework for data augmentation. In particular, our formalism requires explicit models of the underlying artifacts and the desired reconstruction in their presence to augment the original training set with simulations of these artifacts.
We define the class of “artifact-generating” transformations as S such that if 𝒯 ∈ S, then 𝒯 = 𝒯R ⊗ 𝒯L for 𝒯R : ℝn1 × n2 × n3 → ℝn1 × n2 × n3 and 𝒯L : {0, 1}n1 × n2 × n3 → {0, 1}n1 × n2 × n3, where 𝒯R acts on an n1 × n2 × n3 raw image and 𝒯L acts on its corresponding label image. For example, the common augmentation step of rotation by 90∘ can be realized by 𝒯R and 𝒯L both rotating their arguments by 90∘. Data augmentation adds these rotated raw/label image pairs to the original training set (Fig.
Occluded branches: Branch occlusions can be caused by photobleaching or an absence of a fluorophore. We model the artifact-generating transformation for an absence of a fluorophore as 𝒯 = 𝒯R ⊗ ℐ, where
𝒯ℛ(R; x, y, z) = R − PSF(x, y, z)
such that ℐ denotes the identity transformation, x denotes the position of the absent fluorophore and PSF is its corresponding point-spread function. Here, we approximated the PSF of a fluorophore with a multivariate Gaussian.
Duplicate sections: The stage of a scanning 3D microscope can intermittently stall, which can duplicate the imaging of a tissue section. The artifact-generating transformation for stage stalling is given by 𝒯 = 𝒯R ⊗ ℐ, where
$$\mathcal{T_R}(R; \mathbf{r}, \mathbf{r_0}, N)
=
\begin{cases}
R(\mathbf{r}), \mathbf{r} \not\in N \\
R(\mathbf{r_{0}}), \mathbf{r} \in N
\end{cases}$$
for the region r = (x, y, z) and the plane r0 = (x0, y, z) such that 𝒯R duplicates the slice r0 in a rectangular neighborhood N.
Dropped sections: Similar to the stalling of the stage, jumps that result in missed sections can occur intermittently. The corresponding artifact-generating transformation is given by 𝒯 = 𝒯R ⊗ 𝒯L, where
$$\mathcal{T}_{R}(R; \mathbf{r}, x_0, \Delta)
=
\begin{cases}
R(x, y, z), & x \leq x_0 \\
R(x + \Delta, y, z), & x > x_0
\end{cases}$$
and
$$\mathcal{T}_{L}(L; \mathbf{r}, x_0, \Delta)
=
\begin{cases}
L(x, y, z), & x \leq x_0 - \Delta \\
L(D(x), y, z), & |x-x_0-\frac{\Delta}{2}| > \frac{3\Delta}{2} \\
L(x + 2\Delta, y, z), & x \geq x_0 + 2\Delta
\end{cases}$$
such that r = (x, y, z), for D(x, x0, Δ) = x0 − Δ + 3/2⌈x − x0 + Δ⌉, which downsamples the region to maintain partial connectivity in the label. Hence, 𝒯R skips a small region given by Δ at x0, and 𝒯L is the corresponding desired transformation on the label image.
Stitching misalignment: Misalignments can occur between 3D image stacks, potentially causing topological breaks and mergers between neuronal branches. The corresponding artifact-generating transformation is given by 𝒯 = 𝒯R ⊗ 𝒯L, where
$$\mathcal{T}_{R}(R;x,y,z,\Delta)
=
\begin{cases}
R(x, y, z), & x \leq x_{0} \\
R(x, y + \Delta, z), & x > x_{0}
\end{cases}$$
and
$$\mathcal{T}_{L}(L;x,y,z,\Delta)
=
\begin{cases}
L, & x \leq x_{0} - \frac{1}{2} \Delta \\
\Sigma_{zy}(\Delta) L, & |x-x_{0}|<\frac{1}{2} \Delta \\
L(x, y + \Delta, z), & x > x_{0} + \frac{1}{2} \Delta
\end{cases}$$
such that Σzy(Δ) is a shear transform on L. Hence, 𝒯R translates a region of R to simulate a stitching misalignment, and 𝒯L shears a region around the discontinuity to maintain 18-connectivity in the label.
Light scattering: Light scattering by the cleared tissue can create an inhomogeneous intensity profile and blur the image. To simulate this image artifact, we assumed the scatter has a homogeneous profile and is anisotropic due to the oblique light-sheet. We approximate these characteristics with a Gaussian kernel: G(x, y, z) = G(r) = 𝒩(r; μ, Σ). In addition, the global inhomogeneous intensity profile was simulated with an additive constant. Thus, the corresponding artifact-generating transformation is given by 𝒯 = 𝒯R ⊗ ℐ, where
𝒯R(R) = R(x, y, z) * G(x, y, z) + λ
Fully automated, scalable tracing
To optimize the pipeline for scalability, we store images as parcellated HDF5 datasets. For training, a file server software streams these images to the GPU server, which performs data augmentations on-the-fly, to minimize storage space requirements. For deploying the trained neural network, the file server similarly streams the datasets to a GPU server for segmentation. Once the segmentation is completed, the neuronal morphology is reconstructed automatically from the segmented image using the UltraTracer neuron tracing tool within the Vaa3D software package
Experimental Procedure
In our experiments, we used a dataset of 54 manually traced neurons imaged using oblique light-sheet microscopy. These morphological annotations were dilated while preserving topology for training the neural network for segmentation. We partitioned the dataset into training, validation, and test sets by randomly choosing 25, 8, and 21 neurons, respectively. The software package PyTorch was used to implement the neural network
Results
Topologically accurate reconstruction
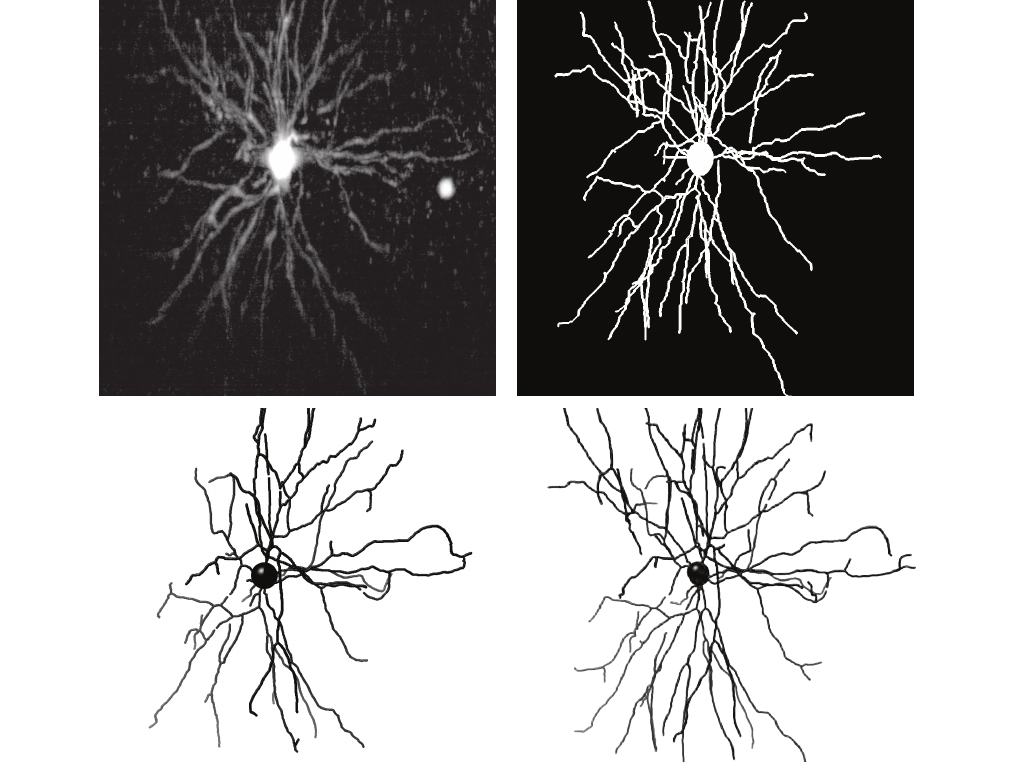
To quantify the topological accuracy of the network on light-sheet microscopy data, we define the topological error as the number of non-simple points that must be added or removed from a prediction to obtain its corresponding label. Specifically, for binary images L̂ and L, let 𝒲(L̂, L) denote a topology-preserving warping of L̂ that minimizes the voxelwise disagreements between the warped image and L
$$J(\hat{L}, L) = \frac{c(\mathcal{W}(\hat{L}, L) \cap L)}{c(\mathcal{W}(\hat{L}, L) \cup L)}.$$
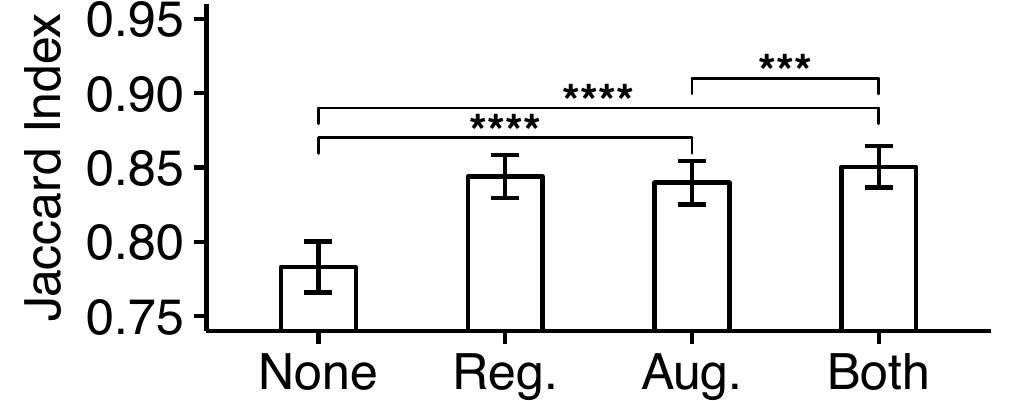
We compared this score across different U-Net results: without any augmentations or regularization, with the augmentations, with the topological regularization, and with both the topological regularization and the augmentations. The U-Net results with augmentations and topological regularization performed significantly better compared to the results without augmentations or regularization (Figs 2, 3).
Neuron reconstruction is efficient and scalable
To quantify the efficiency of the distributed framework, we measured the framework’s throughput for augmenting data, training on the data, and segmenting the data. Augmentations performed at 35.2 ± 9.2 gigavoxels per hour while training performed at 16.8 ± 0.2 megavoxels per hour. Segmentation performed at 348.8 ± 1.9 gigavoxels per hour. Both segmentation and training showed a linear speedup with an additional GPU. For an entire mouse brain, neuronal reconstruction would take about 23 hours on a single GPU.
Discussion
In this paper, we proposed an efficient, scalable, and accurate algorithm capable of reconstructing neuronal anatomy from light microscopy images of the whole brain. Our method employs topological regularization as well as simulates discontinuous image artifacts inherent to the imaging systems. These techniques help maintain topological correctness of the trace (skeleton) representations of neuronal arbors.
While we demonstrated the merit of our approach on neuronal images obtained by oblique light-sheet microscopy, our methods address some of the problems common to most 3D fluorescence microscopy techniques. Therefore, we hope that some of our methods will be useful for multiple applications. Combined with the speed and precision of oblique light-sheet microscopy, the distributed and fast nature of our approach enables the production of a comprehensive database of neuronal anatomy across many brain regions and cell classes. We believe that these aspects will be useful in discovering different cortical cell types as well as understanding the anatomical organization of the brain.
Bertrand, Gilles, and Grégoire Malandain. 1994. “A New Characterization of Three-Dimensional Simple Points.” Pattern Recognition Letters 15 (2). Elsevier: 169–75.
Briggman, Kevin, Winfried Denk, H. Sebastian Seung, Moritz N. Helmstaedter, and Srinivas C. Turaga. 2009. “Maximin Affinity Learning of Image Segmentation.” In Advances in Neural Information Processing Systems, 1865–73.
Chung, Kwanghun, Jenelle Wallace, Sung-Yon Kim, Sandhiya Kalyanasundaram, Aaron S. Andalman, Thomas J. Davidson, Julie J. Mirzabekov, et al. 2013. “Structural and Molecular Interrogation of Intact Biological Systems.” Nature 497 (7449). Nature Publishing Group: 332.
Çiçek, Özgün, Ahmed Abdulkadir, Soeren S. Lienkamp, Thomas Brox, and Olaf Ronneberger. 2016. “3D U-Net: Learning Dense Volumetric Segmentation from Sparse Annotation.” In International Conference on Medical Image Computing and Computer-Assisted Intervention, 424–32. Springer.
Denk, Winfried, and Heinz Horstmann. 2004. “Serial Block-Face Scanning Electron Microscopy to Reconstruct Three-Dimensional Tissue Nanostructure.” PLoS Biology 2 (11). Public Library of Science: e329.
Gala, Rohan, Julio Chapeton, Jayant Jitesh, Chintan Bhavsar, and Armen Stepanyants. 2014. “Active Learning of Neuron Morphology for Accurate Automated Tracing of Neurites.” Frontiers in Neuroanatomy 8. Frontiers: 37.
Helmstaedter, Moritz, Kevin L. Briggman, Srinivas C. Turaga, Viren Jain, H. Sebastian Seung, and Winfried Denk. 2013. “Connectomic Reconstruction of the Inner Plexiform Layer in the Mouse Retina.” Nature 500 (7461). Nature Publishing Group: 168.
Jain, Viren, Benjamin Bollmann, Mark Richardson, Daniel R. Berger, Moritz N. Helmstaedter, Kevin L. Briggman, Winfried Denk, et al. 2010. “Boundary Learning by Optimization with Topological Constraints.” In Computer Vision and Pattern Recognition (Cvpr), 2010 Ieee Conference on, 2488–95. IEEE.
Kingma, Diederik P., and Jimmy Ba. 2014. “Adam: A Method for Stochastic Optimization.” ArXiv, December.
Lee, Kisuk, Jonathan Zung, Peter Li, Viren Jain, and H. Sebastian Seung. 2017. “Superhuman Accuracy on the SNEMI3D Connectomics Challenge.” ArXiv, May.
Lein, Ed S., Michael J. Hawrylycz, Nancy Ao, Mikael Ayres, Amy Bensinger, Amy Bernard, Andrew F. Boe, et al. 2007. “Genome-Wide Atlas of Gene Expression in the Adult Mouse Brain.” Nature 445 (7124). Nature Publishing Group: 168.
Narasimhan, Arun, Kannan Umadevi Venkataraju, Judith Mizrachi, Dinu F. Albeanu, and Pavel Osten. 2017. “Oblique Light-Sheet Tomography: Fast and High Resolution Volumetric Imaging of Mouse Brains.” BioRxiv. https://doi.org/10.1101/132423.
Paszke, Adam, Sam Gross, Soumith Chintala, Gregory Chanan, Edward Yang, Zachary DeVito, Zeming Lin, Alban Desmaison, Luca Antiga, and Adam Lerer. 2017. “Automatic Differentiation in PyTorch.” NIPS.
Peng, Hanchuan, Zhi Zhou, Erik Meijering, Ting Zhao, Giorgio A. Ascoli, and Michael Hawrylycz. 2017. “Automatic Tracing of Ultra-Volumes of Neuronal Images.” Nature Methods 14 (4). Nature Publishing Group: 332.
Ronneberger, Olaf, Philipp Fischer, and Thomas Brox. 2015. “U-Net: Convolutional Networks for Biomedical Image Segmentation.” In Medical Image Computing and Computer-Assisted Intervention – Miccai 2015, edited by Nassir Navab, Joachim Hornegger, William M. Wells, and Alejandro F. Frangi, 234–41. Cham: Springer International Publishing.
Susaki, Etsuo A., Kazuki Tainaka, Dimitri Perrin, Fumiaki Kishino, Takehiro Tawara, Tomonobu M. Watanabe, Chihiro Yokoyama, et al. 2014. “Whole-Brain Imaging with Single-Cell Resolution Using Chemical Cocktails and Computational Analysis.” Cell 157 (3). Elsevier: 726–39.
Sümbül, Uygar, Sen Song, Kyle McCulloch, Michael Becker, Bin Lin, Joshua R. Sanes, Richard H. Masland, and H. Sebastian Seung. 2014. “A Genetic and Computational Approach to Structurally Classify Neuronal Types.” Nature Communications 5 (3512).
Sümbül, Uygar, Aleksandar Zlateski, Ashwin Vishwanathan, Richard H. Masland, and H. Sebastian Seung. 2014. “Automated Computation of Arbor Densities: A Step Toward Identifying Neuronal Cell Types.” Frontiers in Neuroanatomy 8. Frontiers: 139.
Türetken, Engin, Fethallah Benmansour, and Pascal Fua. 2012. “Automated Reconstruction of Tree Structures Using Path Classifiers and Mixed Integer Programming.” In Computer Vision and Pattern Recognition (Cvpr), 2012 Ieee Conference on, 566–73. IEEE.
Türetken, Engin, Germán González, Christian Blum, and Pascal Fua. 2011. “Automated Reconstruction of Dendritic and Axonal Trees by Global Optimization with Geometric Priors.” Neuroinformatics 9 (2-3). Springer: 279–302.
Wang, Yu, Arunachalam Narayanaswamy, Chia-Ling Tsai, and Badrinath Roysam. 2011. “A Broadly Applicable 3-D Neuron Tracing Method Based on Open-Curve Snake.” Neuroinformatics 9 (2-3). Springer: 193–217.